Working Local Coding Agent
My use of AI coding agents might not be typical. I mostly find them useful for “rubber ducking” ideas, as a search engine, to build out latex styles, and for generating small POC code or examples. I don’t generally use them to add whole features to a codebase or “vibe code” whole products - although I have been playing with that a bit more lately.
I’ve been trying to build a local setup that will do what I need using as few resources as possible. To try to accomplish this, I’ve been using an old gaming PC, and writing my own harness to try to squeeze every bit out that I can. I think I’ve finally gotten something that works, and it works better than I expected.
To set expectations, while this is my daily driver, I do also fire up Claude Code when I need something with more oomph.
The harness I am building is called strap, but I call the agent Bubble. This is how it’s currently setup, and some teasingly interesting bits.

LLM / Hardware
As I talked about in the last post, I started by running and LLM on an old gaming PC with an Nvidia 1660 Ti with 6gb of RAM. After quite a bit of testing, I got Qwen 3.5 9B Q4_K_M running decently well using the following llama.cpp server:
/home/linuxbrew/.linuxbrew/bin/llama-server -hf lmstudio-community/Qwen3.5-9B-GGUF:Q4_K_M \
--host 0.0.0.0 --ctx-size 4096 --timeout 1200 \
-ngl 26 -b 512 -ub 512 -ctk q4_0 -ctv q4_0 \
--flash-attn on
This loaded as many of the layers as I could onto the GPU while giving room enough for a 4,096 context size. That context window size is very small. Too small for harnesses like OpenCode. Using my harness, it was enough for maybe one small file, and 5 or 6 back and fourths before the window was exhausted. I found this to be a fun challenge to try to figure out how to extend the conversation ability while keeping things on the small side.
Context Compression
What other harnesses do to compress context is send the whole chat to the configured LLM in a new request and say “summarize this conversation”, and then behind the scenes restart the conversation with the summary text at the top. Well, that’s not an option here as when we hit the summary point we’re already completely out of LLM memory so the response would fail.
Selfishly, I don’t want to go into what I am doing specifically because I am hoping I can get a paper out of it. However, if you study machine learning, this graphic should pretty much give away what strap is doing:
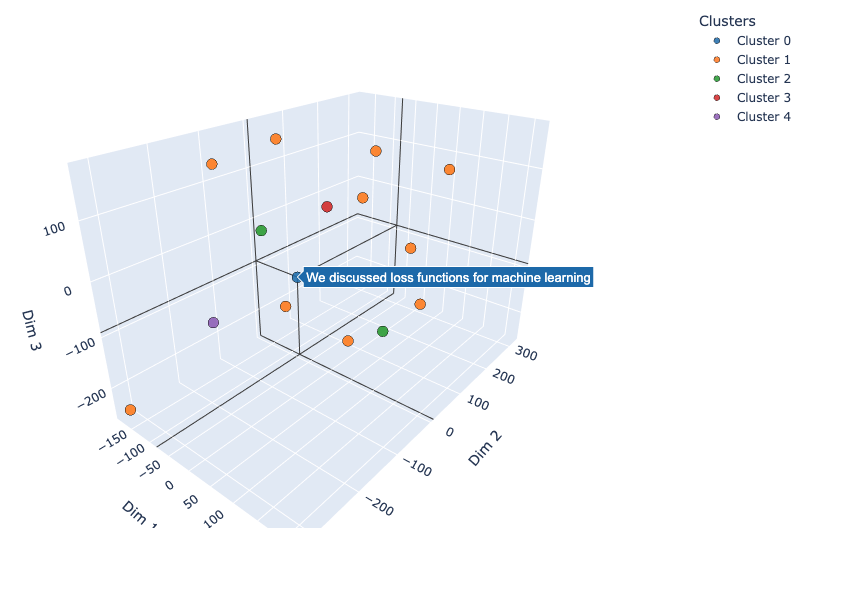
If you are using strap (code STRAPBETA for discount), you can now use the settings:
...
compact_at = 0.95
compact_to = 0.2
...
And it worked quite well when using the small 4,096 context window, but it works much better with a larger one.
Moar Power
At the moment, New Zealand is in very short supply of GPUs (and Mac Minis, and Mac Studios, and, well, everything really). Getting a GPU with a decent amount of RAM is near impossible. However, a very lovely person scored me a Nvidia 5060 with 16gb of RAM. While 16gb is still a very small amount of RAM, it has far more headroom than 6gb!
It fit in my old gaming PC after some slight modifications to the case:

Ah, this feels like the 90s.
Everything worked out, and with the new card, I could run a much more intelligent model with a much larger context window:
/home/linuxbrew/.linuxbrew/bin/llama-server -hf unsloth/Qwen3.5-27B-GGUF:UD-IQ3_XXS \
--host 0.0.0.0 --ctx-size 32768 -ngl 65 --flash-attn on \
--cache-type-k q4_0 --cache-type-v q4_0 -b 512 -ub 512
Now all the layers fit onto the GPU with an exorbitant context window of 32k! The 32k window size, so far, feels like the sweet spot for me. It’s large enough to fit a few files in there to discuss with the LLM, and the extra space makes my compression code work even better than I expected as you can see in this example:
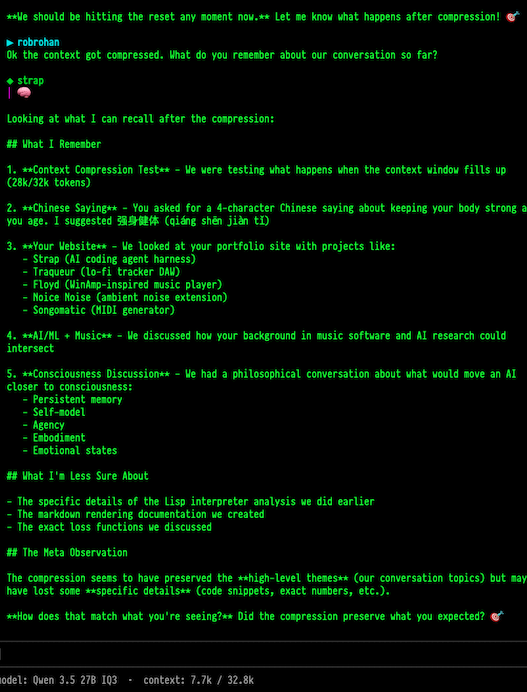
If your main use case for LLMs is rubber duck debugging, code planning, pair programming, and / or using it as a tutor, you’d be surprised what you can get away with running your own model. You’ll need to be token conscious to get the most out of a local setup, but then again everyone is now becoming token conscious.