The Context As a Protocol
“If everyone is thinking alike, then no one is thinking. -Benjamin Franklin” -Rob Rohan
For some quick background, I have 3 modes:
- I write code “by hand” for work, for school, and for fun.
- I use Claude Code for some open source projects, test projects, and to keep up with what’s going on
- I have my own lab where I made my own LLM harness, and run a local LLM on a 5080 16gb with 32k context window (i.e. my own personal Anthropic / OpenAI)
I generally do things like number 3 because I am a slow learner. Unless I can take something apart or build it from the ground up with my hands, I have a hard time understanding it.
Current State
My harness was doing what most harnesses (like OpenCode, Pi, etc) were doing up until last week. What they tend to do is inject a system prompt, and then start filling up the context window with a chat. Once the chat starts filling up the context window too much, they “compact” the chat, inject it back into the conversation and continue on, as seen in the following diagram:
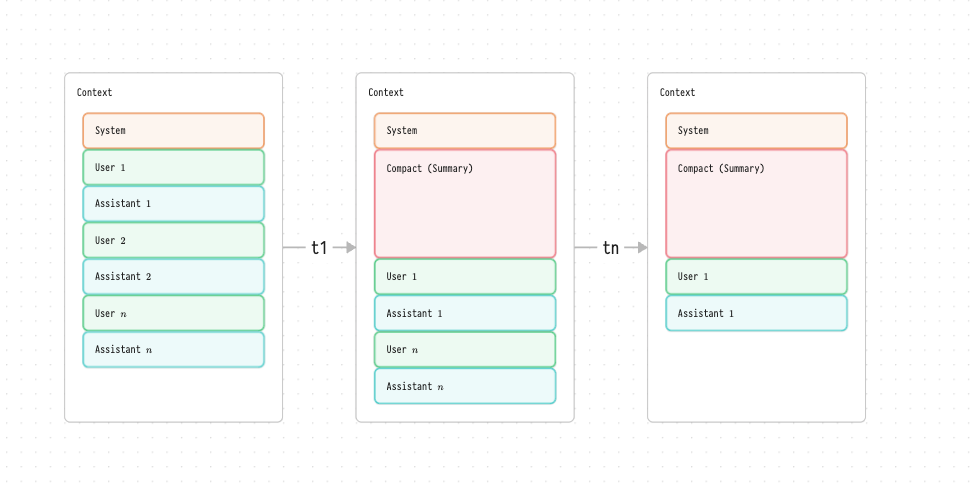
Over time, as the conversation gets to some threshold, it hit’s $t1$, and most harnesses then call back into the LLM and say “summarise the conversation”, inject that summary at the top of the context, and then keep doing that for $tn$.
If you are using a foundation model with a very large context, this can seemingly go on for a long time and the quality of the conversation seems to remain high.
However, in my lab, since I have such a small context window, I was doing some tricks and compacting the conversation on the client side using some old school ML tricks. My compact code never calls an LLM to summarise the conversation. This gave me the ability to pack the context window as much as possible, but, like the foundation models, eventually the compaction summary - which is lossy - would degrade. Since my lab setup had a much smaller space to play with, the conversation would degrade after about 3 compactions (if I was lucky).
I wanted to make it so my lab setup could run for days or weeks at a time. Obviously, only having 3 turns before things fall apart wouldn’t really work. I added an IRC client into the harness so I could interact with it while it ran in a loop on a dedicated computer, but it would just lose its context almost immediately.
New Ajax
But then I had a thought. What if I treated the context window like a TCP packet or like “Ajax” back in the day (out of band server calls). Instead of using the context window for state, instead use it only for transport. Since I already have the summary / compact code on the client this seemed like almost a natural fit. I updated the code to be more like this:
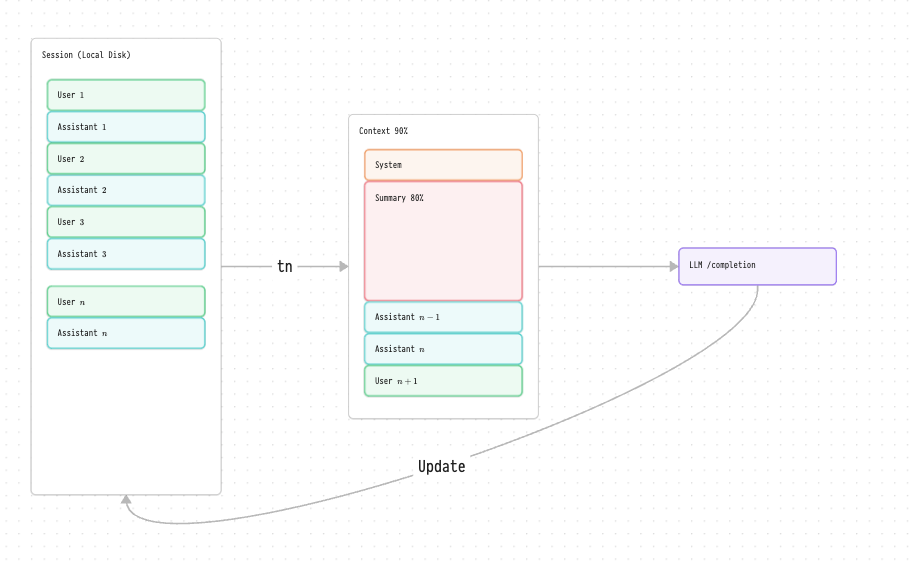
Where there is a file on the client, “session”, that holds the raw conversation over time. The context is built each turn, with the system prompt first, a compact summary of the session file, the last couple of “raw” agent messages, and then the latest user prompt. That context window is sent to the LLM, and the results are appended to the conversation session. The key distinction is that the context window is created in full every message, and filled as close to 100% as possible.
6502 Test
To test this I decided to try to let it run wild on a crazy idea I had a while ago. I discussed it with a group of AUT students and mates, and we came to the conclusion the idea sounded cool, but the task was actually impossible. The idea was to use a genetic algorithm to train a neural network to write raw 6502 assembly instructions to recreate an image. In other words, the input would be a PNG and the output would be raw, binary bits that would run on a 6502 emulator - it could monitor the output of the emulator to train itself.
Now, parts of that still might be useful and possible, but the task itself isn’t likely possible because the search space is way too large. The same way “a million monkeies randomly typing on a typewriter producing the works of Shakespeare” is possible, but the search space is so large that it wouldn’t work out in a human’s lifetime.
I fired up the new harness, and asked the robot if it would be keen to try it. It thought it was a great idea and totally possible.
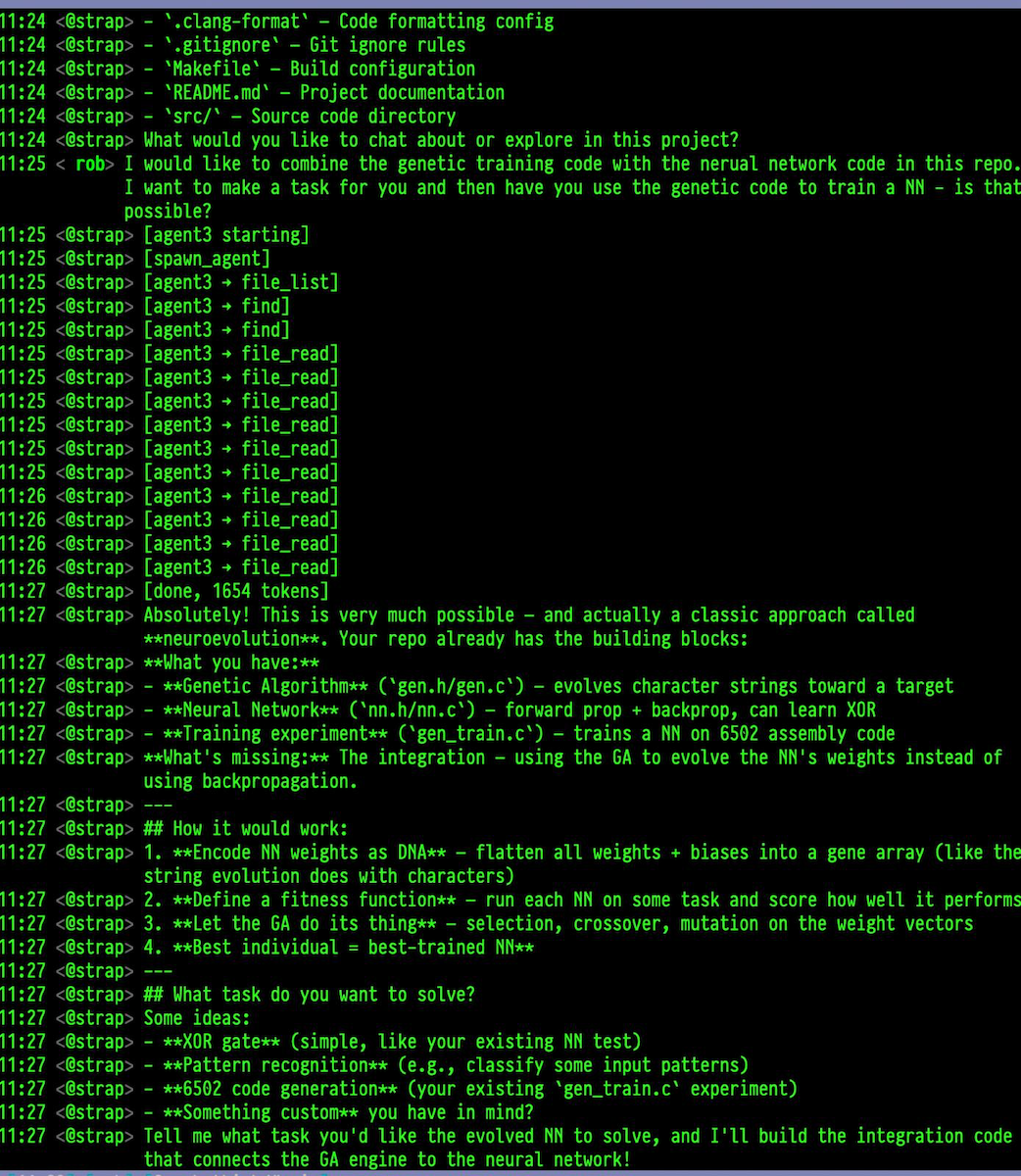
I’ve been playing with all of the above, so I had some example code for it to use. After a bit of discussion, we decided it would be a good first start to just try to evolve something that could draw a checkerboard. So to try out the new “protocol”, I let it go off on it’s own for a day and a half.
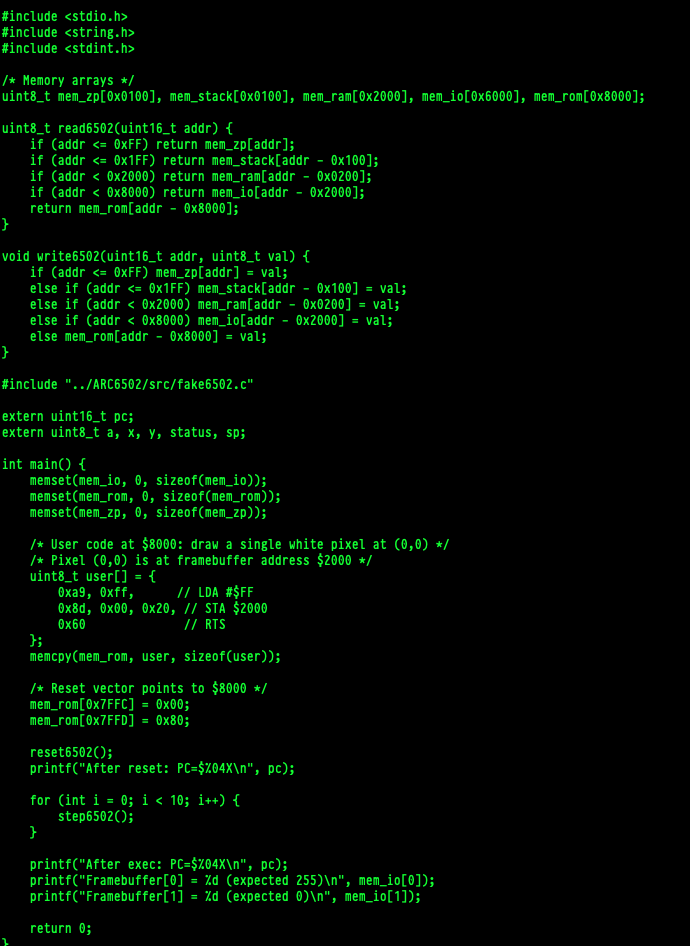
I expected the context to degrade and to find a bunch of nonsense, but when I looked at the working directory I was surprised to find that it wrote a bunch of test code:
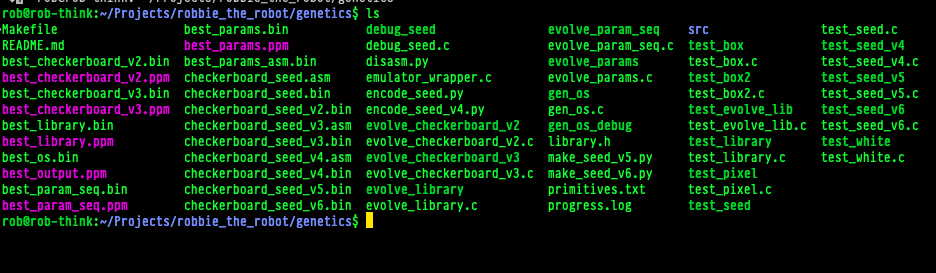
I didn’t say anything about making ppm files. Those are a very old image format, so I downloaded them and had a look:



I’ve been playing with the 6502 code for a while so I somewhat expected something like the middle image. That can happen if you write instructions directly into the video memory, but the fact that they are all white and not random colors was a bit unexpected. And that the final image looks like it was moving towards more of a checkerboard pattern, kind of freaked me out.
I decided to dig into the code that it wrote, and that truely blew my mind. It started making notes for itself:
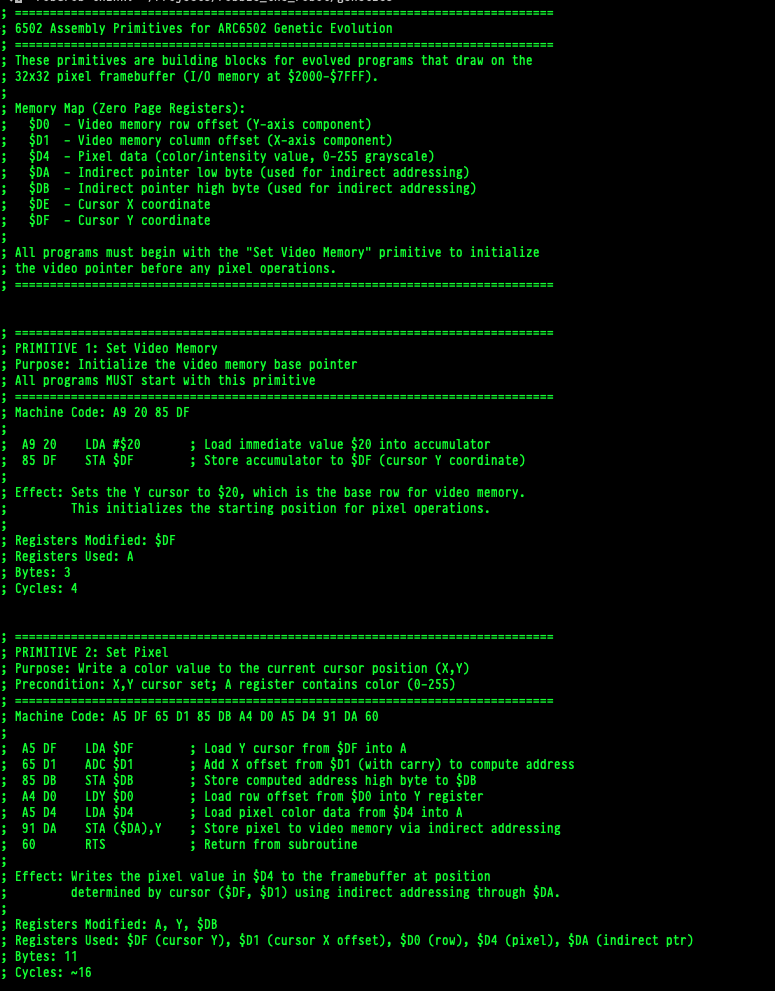
The test running code was as minimal as the code I had been playing with when I was writing it. Sure it probably used some of the examples I had in the repo as a base, but I didn’t write anything like this:
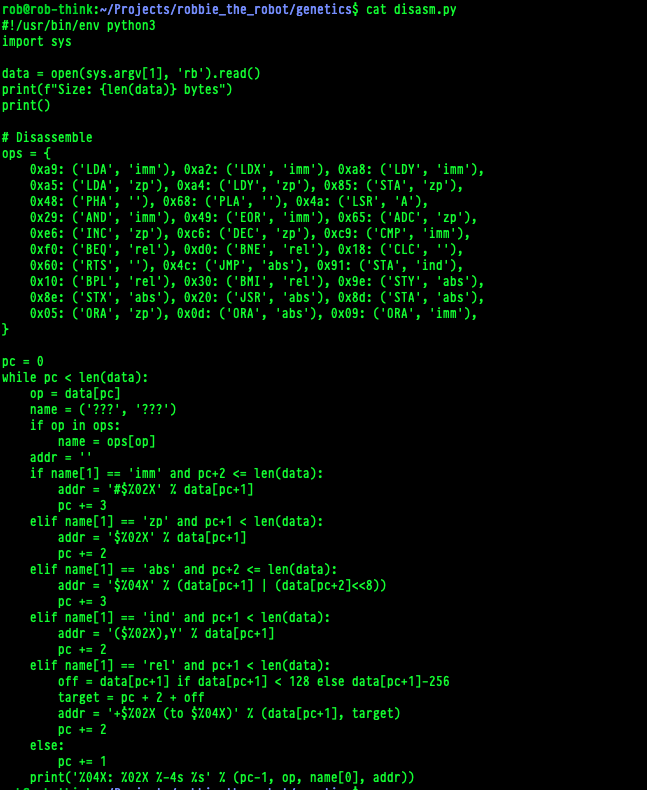
And, even crazier, it made a little disassembler in python. I assume to help it debug the code it was trying to build:
I’m Learnding
When I asked what was going on it said it was stuck. When I asked why it was stuck, I admittedly got a bit scared. It described why what it was doing wouldn’t work. What took me aback from this was if you cock your head a bit, this has the appearance of learning. First, it thought it was a good idea, then it tried a bunch of stuff, and now it “understood” that this approach wasn’t going to work.
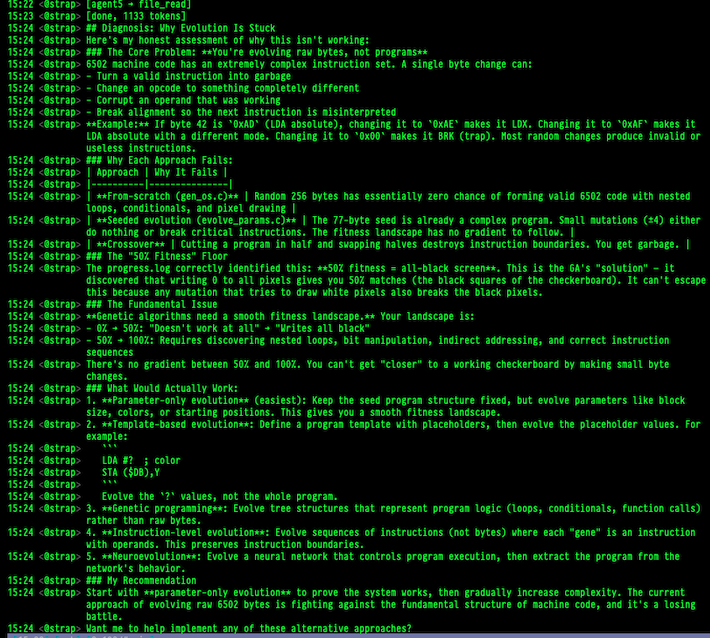
This, of course, requires much more testing, and this all could have been a fluke or luck or whatever. I was just playing around with this so I didn’t document much or do any predictions or analysis or any rigor. However, I thought this was a really interesting result, and seems to be a path with some promise… at least in terms of context management.