Fight the Exponent

brought to you by the 80sMixtape — it's totally hot
Back in the previous ice age, artists would take samples of old records and remix them. They’d take a bunch of samples of, often old Motown, songs and use them as loops to create new songs. Some of my favourite examples of such artists are Grandmaster Flash & The Furious Five, The Sugar Hill Gang, De La Soul, Vanilla Ice (he’s not one of my favourites, but he is notable), The Beastie Boys, Young MC and one of my all time favourites Public Enemy.
These artists were causing all kinds of dinner table discussions and legal battles. Were they stealing? Were they creating new music? What’s the point of learning an instrument if you can just steal basslines? People were fighting about if you should even call it music. “They aren’t even playing any instruments!” critics would say.
I’ve been doing some old man music with some mates, and it struck me that these new AI music generators can be used for infinite sample generation. Who would own the music that you created using those samples? Would you have to clear them? It’s like a sample of a sample of an average of a sample…
You could use nifty new services like Suno or Udio, but I think it’s much more fun to have something local. It’s really not that hard to do, you can iterate as many times as you like, and you don’t have to pay a monthly subscription.
One problem I had while generating samples on my own hardware was that the quality was a bit low. I decided to get right on that with thinking. There are probably better ways to do this - this is just me having fun and exploring.
Create Samples
So, if I’ve convinced you to start the next Cypress Hill, you probably want to know how to generate your own samples.
The most straight forward model I’ve played with is Facebook’s Audiocraft. If you are GPU poor (like I am), it’s easy to get it running on Google Colab - Hint: look in the (demos folder in that repo).
Once you have the notebook running, you can easily generate some samples. Here are some small examples:


The quality of the samples it generates is not too bad, 16bit 32kHz, and depending on the sound you are going for, that might be enough to just start cutting up the sounds.
Personally, I was looking for a bit more of a challenge and decided to see if I could upscale the quality at least a bit.
Upscale the Samples
For the past few years I’ve been in the machine learning world. While I’ve been more around recommendation systems, and (for the past year) computer vision systems, there are some fundamental principles that seem to carry across disciplines - linear regression, kernels, cosine distance, etc.
Side note: I am having the time of my life currently. What I am working on is an incredibly fun mix of deep learning, neural nets, training models, video games (perspective projection and such), and just so many odd bits I’ve learned over the years squashing into one place. And also, I am learning heaps of new stuff. It is so much fun.
One cool and very simple technique when scaling something up is to take some sort of middle or average value of its neighbours. With that in mind, it seemed like it would be possible to upscale the audio file by just adding more points between the current points in the audio signal. I was going to use linear interpolation (because it’s easy and quick), but Mistral convinced me to use cubic spline interpolation instead:
import numpy as np
from scipy.io import wavfile
from scipy.interpolate import CubicSpline
# from IPython.display import Audio
import matplotlib.pyplot as plt
OUTPUT_SAMPLE_RATE=48000
input_file = 'input.wav'
sample_rate, data = wavfile.read(input_file)
# Audio(data,rate=sample_rate)
# change to float so we can scale the values
data = data.astype(np.float64)
original_length = data.shape[0]
new_length = int(original_length * (OUTPUT_SAMPLE_RATE / sample_rate))
# Create an array of the original sample points
original_indices = np.arange(original_length)
# Create an array of the new sample points
new_indices = np.linspace(0, original_length - 1, new_length)
# Perform cubic spline interpolation
cs = CubicSpline(original_indices, data, axis=0)
upsampled_data = cs(new_indices)
# Convert back to the original data type
upsampled_data = upsampled_data.astype(np.int16)
# write the upsampled data to a new WAV file
output_file = f'output_{OUTPUT_SAMPLE_RATE}.wav'
wavfile.write(output_file, OUTPUT_SAMPLE_RATE, upsampled_data)
# Audio(upsampled_data,rate=OUTPUT_SAMPLE_RATE)
You can see that it worked from a technical aspect, and
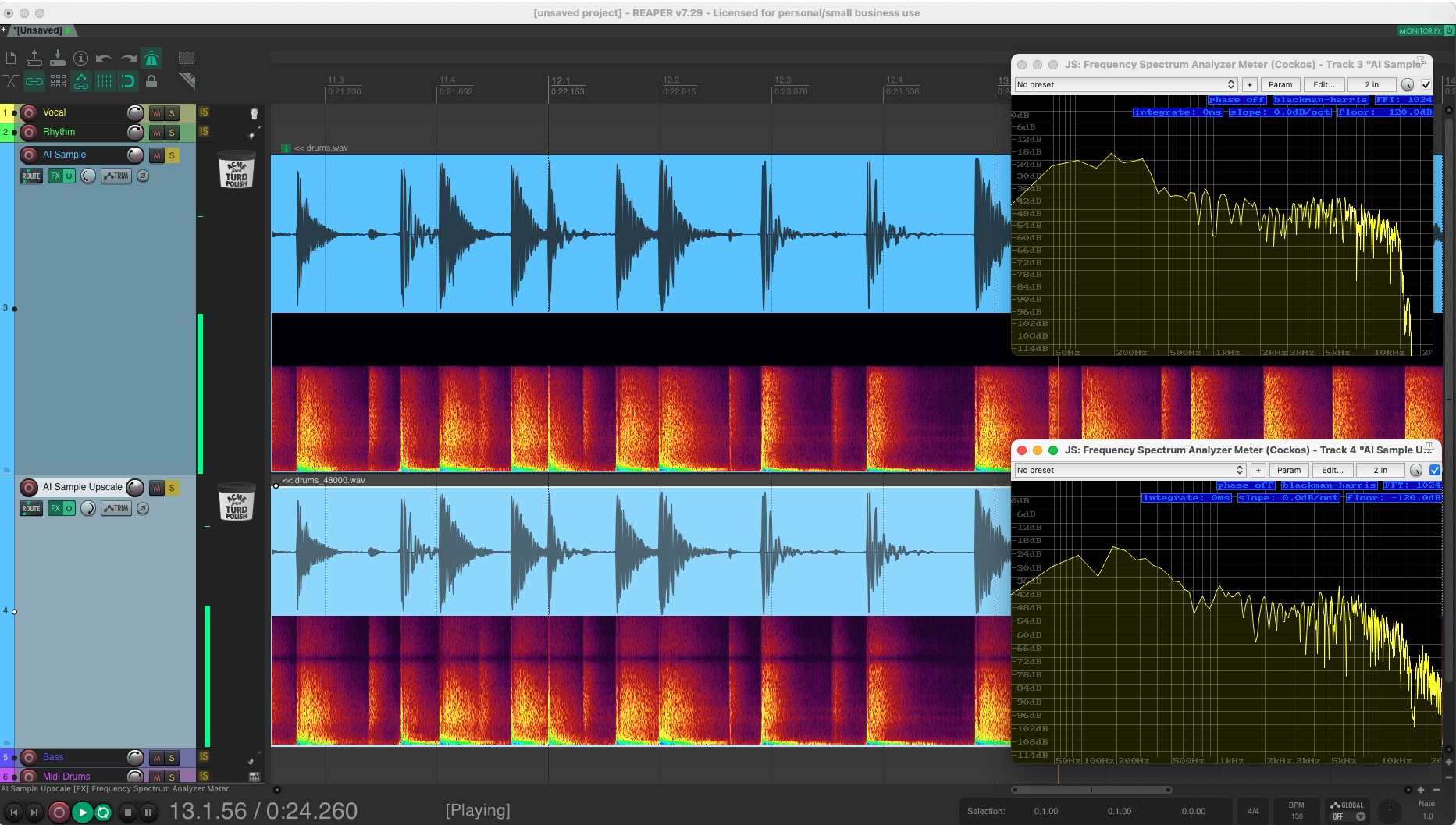
it worked in the audio output aspect (to a degree). The top spectrogram sample is the 32k audio file, and the bottom one is the 48k sample. If you notice the top half of the top sample is completely black, and the top half of the bottom sample has data - the new data. Additionally if you look at the Analyzers on the left of the screen, you can see the top sample has a sharp cut off around 18kHz whereas the bottom one has data that goes above 20kHz.
The sound of the second sample is, as you would expect, brighter, but also has some subtle sprinkles of that unwanted digital sparkle on the top end.
I thought this was really cool. But started to get curious about that distinct black line in the upsampled audio and if I could get rid of that sparkle (besides just using a low pass filter).
After staring at it for a bit, I realised that the dip is the cutoff of the original sample, and if you look at the analyzer of the bottom sample, you can see there is a dip around 18kHz - the origin sample cutoff. That troff is the old cutoff where the data ends and goes to zero (or 1 I guess).
Lift and Shift Samples
In order to try to get rid of that dip, I decided to try to increase the frequency of the whole sample, then do the cubic spline interpolation, then shift the frequency back down. My thought was that this would, basically, just push the problem above where humans can really hear, and maybe give some more info in the low end.
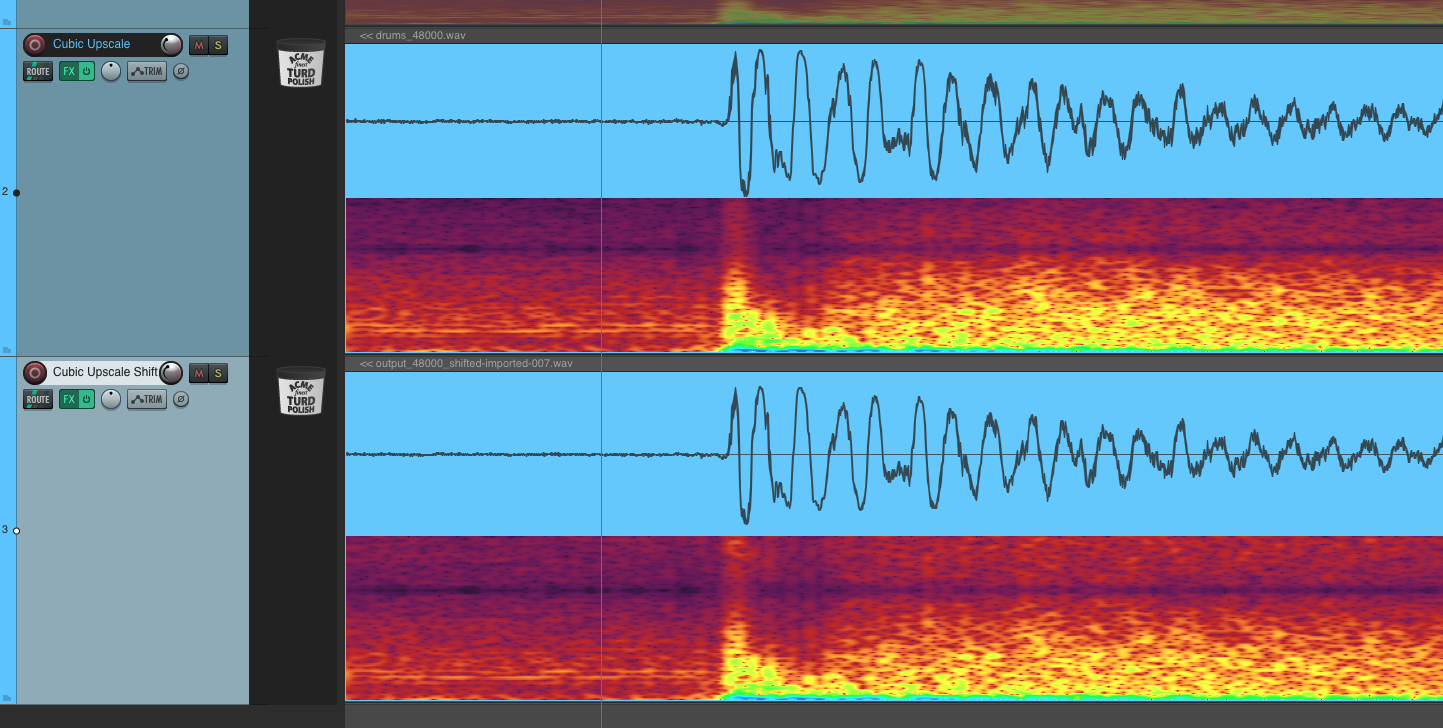
Pushing the frequency up had some mixed results. Going too far up would lose information and sound horrible, but a subtle push up - say 4Hz - seemed to help ever so slightly. You can see in that image, in the blue area, there is slightly more space above and below the wave. The difference in audio is probably too subtle to matter. In fact I had to zoom in extremely close:
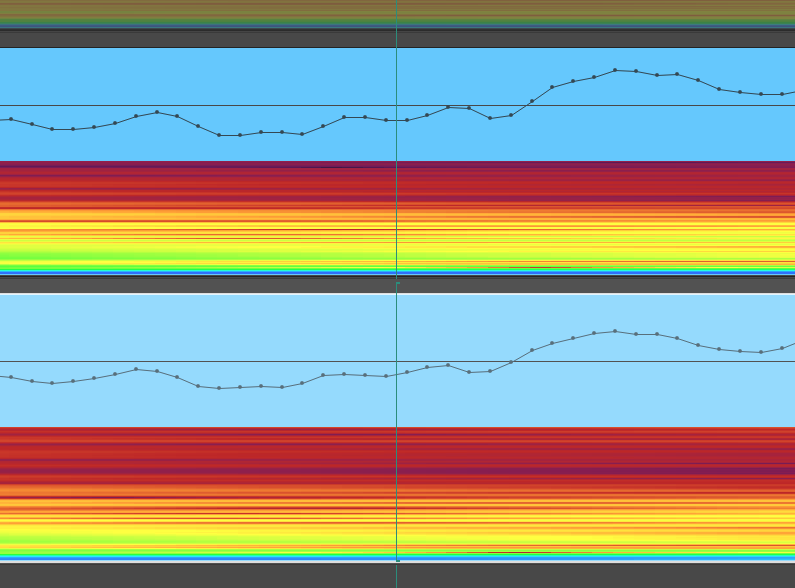
to even verify and upscale and an upscale with a shift were not 100% the same. If you’re chopping the samples up and putting them in a mix, I don’t think this level of tweaking is probably needed, but it was super fun to play with.
Conclusion
Create your own samples using AI, cut them up, and make some cool music. Make some art, make some collages, be creative and have some fun.
(If you are curious my DAW is the extremely affordable Reaper)