Midi GPT custom BPE - Theremin Midi
🕶️ Quick jump if you are just looking for the code, or just looking for the weights.
I wouldn’t call myself a musician, but I’ve been playing and recording music since I was a teenager. It’s a hobby of mine that I’ve dabbled with for a long time.
One technique I sometimes use when I am looking for musical ideas is to roll some dice to inspire chord progressions or melodies. Since I’ve been doing more machine learning work over the past few years, I decided it would be a fun project to create a machine learning model to aid in generating musical ideas.
🕶️ I have a tendency to ramble, but if you’re here for the interesting stuff, the byte pair encoding section is probably all you want.
Architecture
Version 0
My very first stab at this was using something procedural. I started out using perlin noise to generate midi notes, and then applying another set of rules after that step (different ones for generating drums, chords or melodies).
This works surprisingly well (remember we are generating ideas, not songs), but it does have a very robotic feel. I still use this today to generate idea, but it became more useful to generate training data for the next versions.
Output:

Version 1
The next version was using an LSTM (Long short-term memory) RNN (recurrent neural network) architecture. It is, pretty much completely, built from this Tensorflow example. If you would like to learn about this type of architecture, that is a great tutorial.
The main thing I did differently in my version was have a few more hidden layers to try to control how many notes got produced.
This also worked quite well and did feel much more natural. However, I didn’t like that this version ignored the note velocity, and I found training it to be very hit and miss. Sometimes I’d get a nice loss curve, and sometimes it would blow out quickly and horribly. I also wanted to get my hands dirty with some newer architectures. I mean, LSTM is very cool, but it’s from like 1997 - I am not even sure cars existed back then.
{kind=link}
Version 2
At some point, I am going to write about my thoughts on AGI, that language itself isn’t intelligence, models passing tests say more about the tests than it does about intelligence, why people are seemingly confusing the map for the terrain… but for now, the relative part of this half thought is: I think music is a language. It’s a language that conveys emotions and states of being instead of linear, simplistic, basic definitions of objects.
Since I consider it a language, I thought a GPT (generative pre-trained transformer) LLM (large language model) model would be the most interesting architecture to try.
In the end here is the output of the GPT model:
🕶️ I am curious what a model trained on human language would “sound like” and if the embedding of spoken language would somehow also map to notes - and I don’t mean text labels matching up, but the actual weights being used for the connections between notes.
Byte Pair Encoder
So, if you’ve built or played with GPT models, you know the input for these is often text. The text is then tokenized into an array of integers, and those integers are used to do a bunch of matrix multiplies.
This array of integers also isn’t as straight forward as you might expect. What happens is that text is tokenized and turned into (essentially) a lookup table, but they are fragments of text - not just word boundaries. For example, here is test site for OpenAIs tokenizer.
One of the bonuses of this approach is you’ll get repeated groups of things as single tokens - making the set smaller.
Since I am teaching myself this stuff, I wasn’t exactly sure how I could take midi notes and turn them into this array of integers. Also, I figured using as much of what already exists is a good idea.
Here is what I was trying to encode:
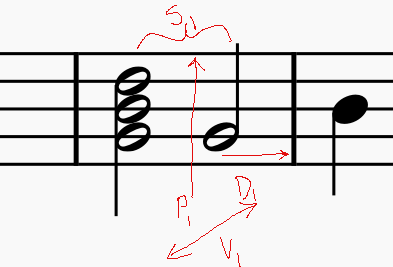
Where:
- S1 is the “step” (the distance in time from the previous note) Notes that share this value make up intervals / chords
- P1 is the pitch of the note (C1, D#4, etc)
- D1 the duration of the note
- V1 is the velocity of the note (how “hard” the note was played)
So what I did was pack several midi dimensions into a single 32-bit integer. Initially using the layout:
| VELOCITY | STEP |
| --------- | --------- |
| 0000 0000 | 0000 0000 |
| DURATION | PITCH |
| --------- | --------- |
| 0000 0000 | 0000 0000 |
Most midi messages are from 0-127 so this layout easily supports 4 different dimensions.
This works, and can do a one to one mapping - one midi note now equals one tokenization point, but I really wanted to map things similarly to how text GPT models work - group bits that are similar into single tokens.
So I took those 32 bit integers, scaled some parts, and then ensured all the correct bits were flipped to ensure that they were always valid UTF-8 characters. The new layout became:
**High Bytes**
| VELOCITY | STEP |
| --------- | --------- |
| XXXX XX00 | XX00 0000 |
| 3 | 63 |
**Low Bytes**
| DURATION | PITCH |
| --------- | --------- |
| XX00 000@ | XX00 0000 |
| 31 | 127 |
Where X are values I can’t touch because they are special to UTF-8 characters. Unfortunately, that means some values need to be scaled down so we lose some fidelity, but I’m trying to make an idea generator so I’m cool with that.
After this change, I can easily encode midi as text. Here is some:
Of course, it’s very high UTF-8 so there probably aren’t any glyphs on your system for those characters, but you can see there are no errors rendering that “string of text”.
With that technique working I could then use Google’s SentencePiece to train a vocabulary model that I can use to tokenize midi to train and do inference on.
Conclusion
While this works, and was super fun to build, it’s probably not practical for the new generation of music generators out there. The technique of encoding 4 dimensions into one integer may be of use in some other contexts. This process is also very fast to train with as you don’t have to load and decode a midi file. It’s also fast on inference, but that is from “the vibes” - I haven’t actually tested it against other solutions.
Credits
- Andrej karpathy the guy who made the minGPT code.
- Google’s tesnsorflow example
- Dr. Tristan Beherns a dude I was having a friendly one sided competition with (his GPT model running in Ableton is cool)
- Dr. Karthik Subra and Dr. William Caicedo-Torres who guided me in particular directions and essentially taught me machine learning in general.