Running Physics in a Webworker
Anyone who knows me knows I wont shut up about this “game engine thing” I am working on. I admit it, I’ve been a bit obsessed.
The reason I am obsessed, I think, is because I get to solve problems that I’ve never really had to solve before. This weekend, for example, I need to make some sort of grid system (or binary space partition) to limit the number of objects I am tossing around in the engine - this kind of stuff never comes up in day to day life! It’s like a crossword puzzle for nerds.
One such problem is trying to fit a whole bunch of work into 16ms. 16ms is the amount of time you have to do all your game processing in order to keep the display at 60 frames per second (which is the standard gaming frame rate). My engine was able to do that, but it was really cutting it close, and I have a lot more I need to add to hit v1.
I decided to rewrite the way I was using the physics system in my engine. I pulled it out of the main game loop and rewrote it into a webworker. I didn’t think this would work. I assumed that I would get a lot of lag, and the collision detection would become easily confused.
However, much to my surprise, it works. Here is a video showing the engine after the rewrite:
To show how much this helped, checkout this performance session from before the rewrite (this is from me walking around that same level):
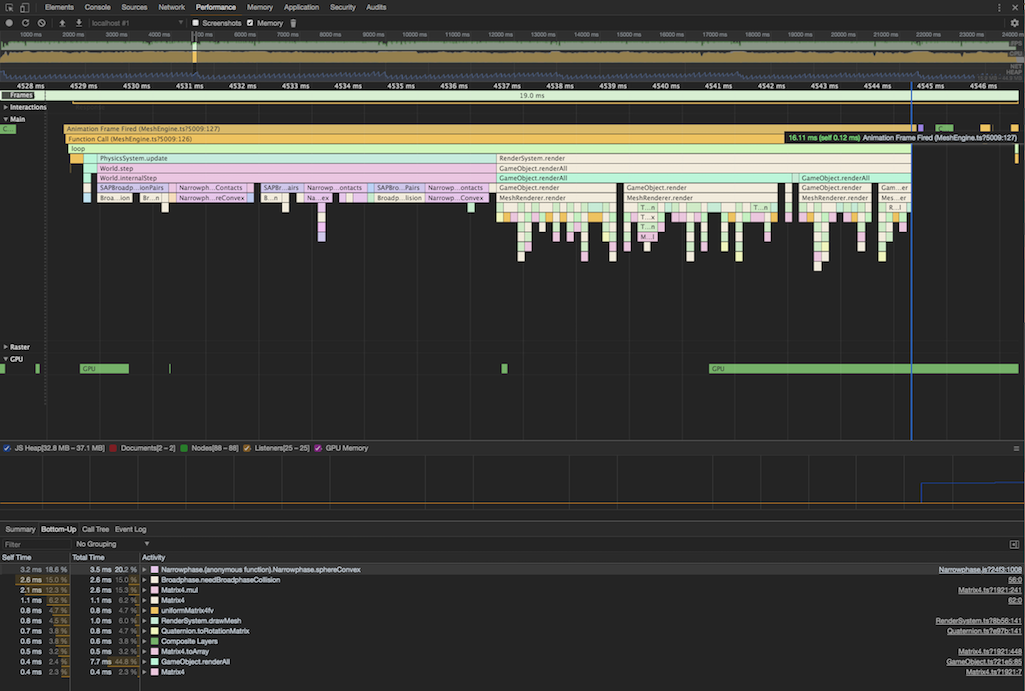
That’s one game loop and you can see it’s right at that 16ms mark. There is not much room for me to add much else to the game. Of course I haven’t tuned / optimized the engine yet, but there really isn’t much room there. My plan was to drop to 30 frames per second if it got down to it.
But now here is a similar session with the web worker:
(Please don’t judge my saw tooth memory too harshly, as I said, I haven’t optimized things yet)
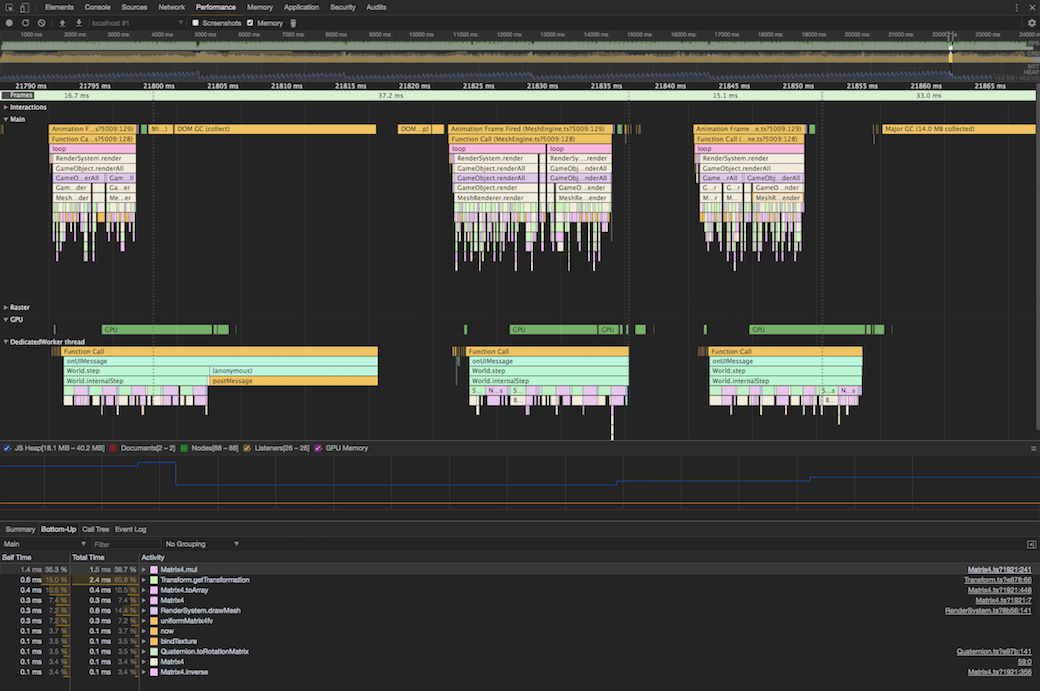
Even with that hard core garbage collection (again tuning…), you can see each game loop cycle is well below 16ms now (easiest to see on that last group of dangly beads).
Zooming in on one group of calls:
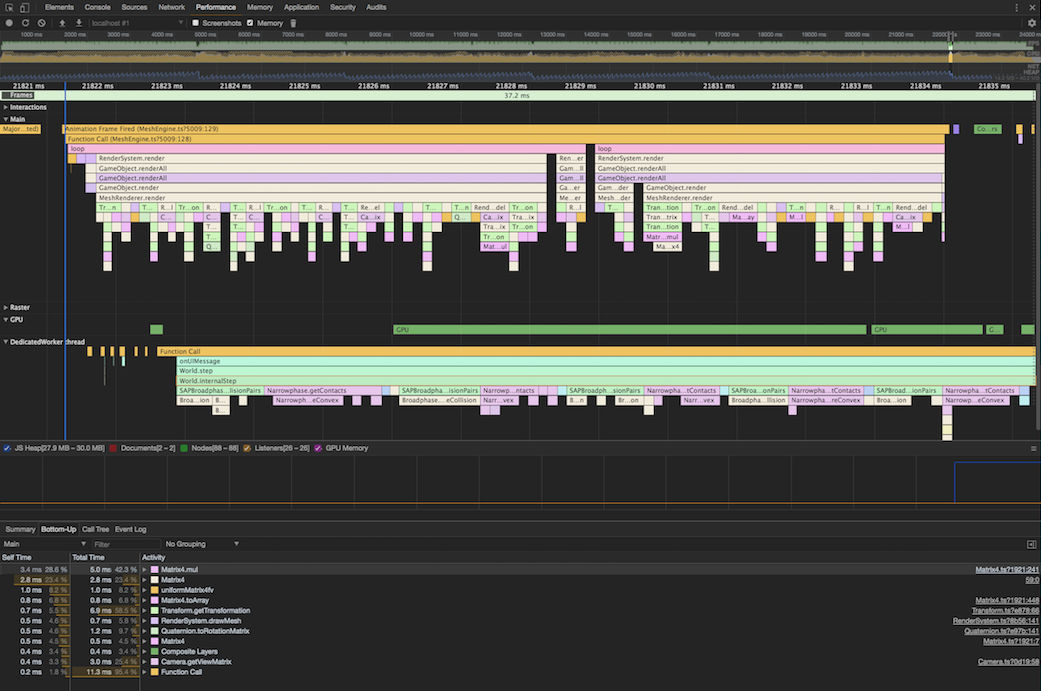
You can really see the parallelism doing beautiful things (and my Matrix4 class being cruel). But the time slice now hovers at about 10-12ms.
I still have a lot of work to do, but this was a nice win.